Secretary - 社交媒体内容 AI 分析工具
国内精选
国内精选
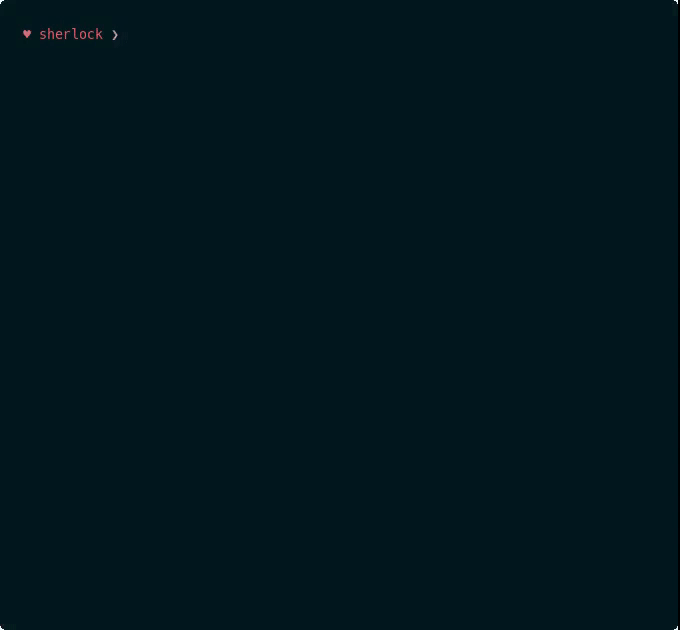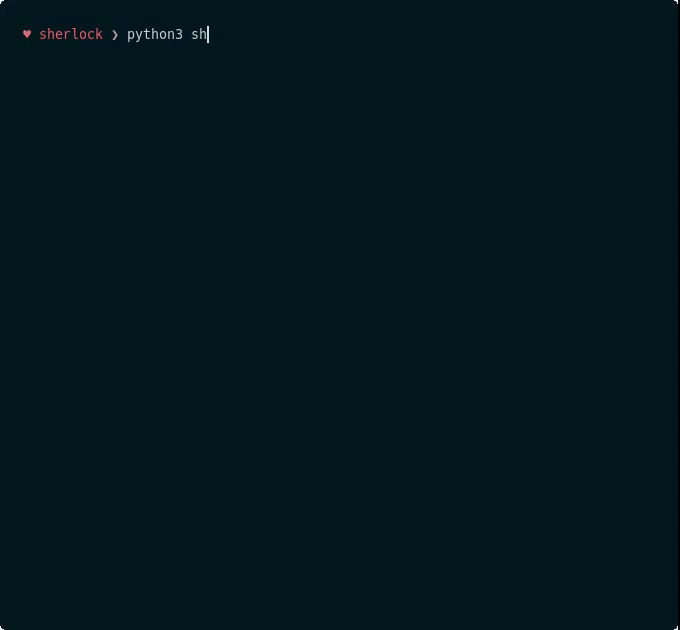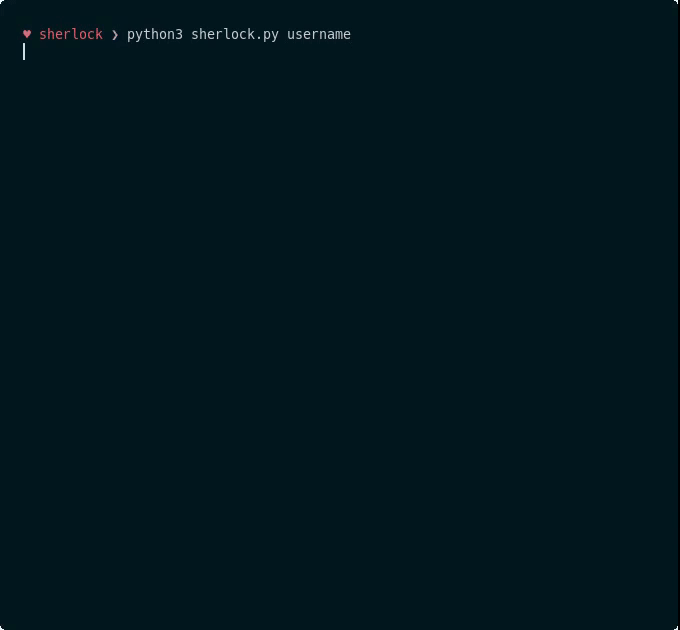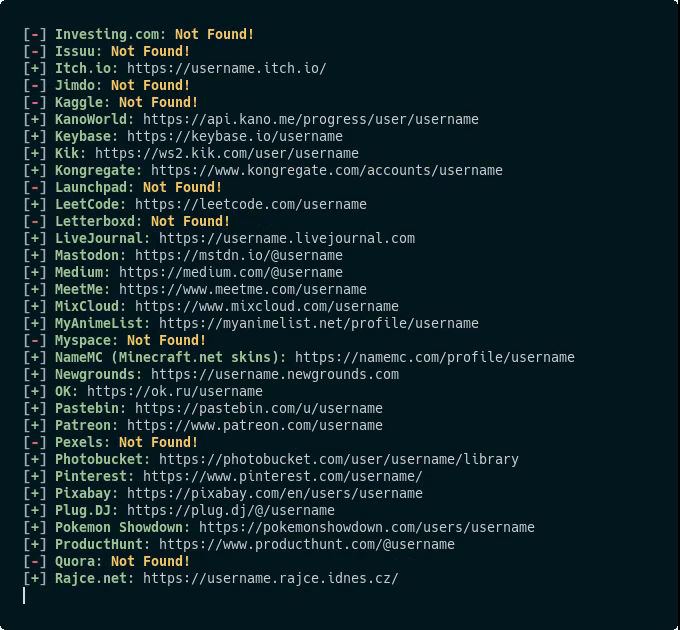
Secretary 是社交媒体内容 AI 分析工具,该工具可自动抓取监控指定账号的最新发表内容,通过 AI 进行分析,并将结构推送到企业/个人微信。 主要功能 支持多平台监控(Twitter 和...
收藏 1

